ソフトウェア脆弱性の「再発」を防ぐには?1,213のOSSプロジェクト分析から紐解くプロセス改善手法
公開日
セキュリティ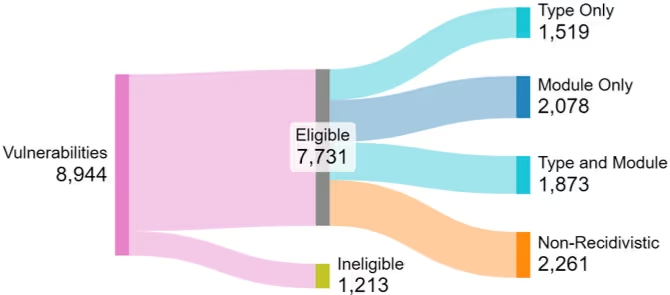
ソフトウェア開発において、不具合やセキュリティ上の欠陥を完全になくすことは容易ではありません。従来のセキュリティ評価では、プロジェクト内で検出された脆弱性の総数をカウントする方法が一般的でした。しかし、脆弱性の件数が多いからといって、必ずしもそのプロジェクトの開発体制が不健全であるとは限りません。積極的に脆弱性を発見し、迅速に修正を重ねているチームの方が、件数は多く見えてもセキュリティ意識が高い場合があるからです。
本記事では、ロチェスター工科大学のBrandon Keller氏による論文「Software Vulnerability Recidivism in Open-Source Projects」に基づき、開発チームが同じ過ちを繰り返している度合いを測る指標「脆弱性再発(Vulnerability Recidivism)」について解説します。本研究は、複数の大規模オープンソースプロジェクトのデータを分析し、開発チームが脆弱性から学習し、プロセスを改善するための新しい評価手法を提示しています。
セキュリティ評価の新しい指標「脆弱性再発」とは?
本研究が提唱する「脆弱性再発」とは、プロジェクト内で過去に発生し、一度は修正されたはずのセキュリティ上の問題が、再び発生してしまう現象を指します。脆弱性の発生件数そのものを減らすことだけでなく、「過去の教訓が開発プロセスに活かされているか」を客観的に評価するための指標です。
脆弱性の特徴を分類する3つのサブタイプ
脆弱性の再発を正確に評価するため、本研究では以下の3つの異なる切り口(サブタイプ)を用いて再発を定義しています。
- タイプ再発(Type Recidivism)
プロジェクト内で、過去に修正されたものと同じ脆弱性タイプが再度発生することを指します。脆弱性のタイプは、一般的に「CWE(共通脆弱性タイプ一覧)」に基づいて分類されます。例えば、過去にSQLインジェクションを修正したにもかかわらず、別の箇所で新たにSQLインジェクションが発生した場合、これはタイプ再発に該当します。 - モジュール再発(Module Recidivism)
過去に脆弱性の修正が行われたのと同じファイルやモジュール(サブシステム)において、再び異なる脆弱性が発生することを指します。同じファイルで何度も脆弱性が検出される場合、そのモジュールの設計や品質管理プロセス自体に根本的な問題が残っている可能性を示唆します。 - ライフタイム再発(Lifetime Recidivism)
脆弱性がコードに混入された時期(Origin)と、それが修正された時期(Fix)の時系列的な前後関係に着目し、開発チームの学習度合いを評価する分類手法です。
 図表1:脆弱性の再発サブタイプの概念的な重なり(概念図)
図表1:脆弱性の再発サブタイプの概念的な重なり(概念図)
時系列で学習度を測定する「ライフタイム再発」の仕組み
ライフタイム再発は、開発チームが「過去の修正から知識を得る機会があったか」を考慮するため、さらに以下の2つのパターンに細分化されます。
- 繰り返し(Repeated)
ある脆弱性が修正された後に、別の同じタイプや同じモジュールの脆弱性が修正されるケースを指します。ただし、新しく修正された脆弱性が、過去の脆弱性の修正よりも前にコードに混入されていた場合、開発チームはまだその問題について学習する機会がなかった(混入時点では知らなかった)と解釈されます。 - 再導入(Reintroduced)
過去の脆弱性が修正された後に、新たに同じタイプや同じモジュールの脆弱性がコード内に混入され、それが後に修正されるケースを指します。これは、チームが一度は修正を経験して学ぶ機会があったにもかかわらず、同じ過ちを再び作り出してしまったことを意味するため、より深刻な開発プロセスの課題(プロセスの欠落や知識共有の不足)を示しています。
1,213プロジェクトの大規模データに見る「再発」の普遍性
脆弱性の再発という現象が、実際のソフトウェア開発においてどの程度一般的であるかを検証するため、本研究では大規模な実証評価が行われました。
【調査概要】対象プロジェクトと脆弱性データの抽出
本研究では、Vulnerability History Project(VHP)が提供する「MegaFoss」データセットを使用し、少なくとも2件以上の脆弱性が報告されている1,213のオープンソースプロジェクトを対象に調査を行いました。合計8,944件のCVE(共通脆弱性識別子)に紐づく修正コミットおよび混入コミット(SZZアルゴリズム等を用いて特定)を分析し、アクティビティを追跡しています。
再発可能な脆弱性のうち約7割で「再発」が発生している現状
分析の結果、脆弱性の再発はオープンソースプロジェクトにおいて極めて普遍的な現象であることが明らかになりました。
調査対象となった全8,944件の脆弱性のうち、最初の1件を除く「再発の可能性がある(再発候補となる)」脆弱性は7,731件存在しました。このうち、全体の約70.8%にあたる5,470件が、何らかの形で「タイプ再発」または「モジュール再発」の条件を満たしていました。
 図表2:1,213プロジェクトにおける脆弱性の再発分類の分布
図表2:1,213プロジェクトにおける脆弱性の再発分類の分布
また、時系列的な「混入時期」を考慮した分析によると、各サブタイプにおける「再導入」と「繰り返し」の件数は、以下のように分類されています。
| 脆弱性タイプ \ モジュール | 再導入(Reintroduced) | 繰り返し(Repeated) | 非再発 |
|---|---|---|---|
| 再導入(Reintroduced) | 243 | 160 | 449 |
| 繰り返し(Repeated) | 46 | 1,424 | 1,070 |
| 非再発 | 272 | 1,806 | 3,474 |
図表3:脆弱性の再発サブタイプ別ライフタイム内訳
「タイプかつモジュール」の両方で再導入が発生したケース(243件)は全体の中では比較的少数ですが、これは「同じファイルに、過去の修正後に、同じタイプの脆弱性を再び作り込んでしまった」という明確な管理ミスを示しています。
コードの複雑度やCVSSスコアといった既存指標との関係
研究では、再発の発生確率と、従来のソフトウェア品質管理で使用される指標との相関関係についても検証されました。
- コードの複雑度(Complexity)との相関
プロジェクトのコード複雑度(sccツール等で測定されたファイル単位の複雑度)と、そのプロジェクトにおける脆弱性再発率との間には、相関関係がほとんど見られませんでした。複雑なコードベースほど脆弱性が混入しやすいという一般的な傾向はありますが、「一度直した脆弱性を繰り返すかどうか」はコードの複雑さそのものよりも、チームの開発プロセスや学習体制に依存している可能性が高いことを示しています。 - 脆弱性の深刻度(CVSS)との相関
CVSS(共通脆弱性評価システム)の基本スコアや各種評価メトリクスについても分析が行われました。その結果、再発した脆弱性と再発しなかった(一回限りの)脆弱性の間で、CVSSの評価値に大きな差異は見られませんでした。これは、再発する問題が必ずしも「軽微な問題」に限定されているわけではなく、重大なセキュリティリスクを持つ脆弱性であっても同様に繰り返されている現実を示しています。
実務で注意すべき「再発」の温床:自動テストとユーティリティファイル
本研究では、開発の実務でよく見られる「自動化されたファズテスト(Fuzzing)」と、共通処理を配置する「ユーティリティ(util)ファイル」の2つの具体的なドメインについて、再発の傾向を詳しく分析しています。
OSS-Fuzzの検出データから見る「修正担当者」の学習機会
Googleが提供する継続的ファズテストサービス「OSS-Fuzz」を利用する588プロジェクト、23,334件のバグ・脆弱性データを分析した結果、自動テストで検出される問題でも高い再発傾向が見られました。
分析によれば、テストで検出された問題の約39.8%において、「脆弱性を混入させた本人(作成者)」がその修正コミットを担当していました。裏を返せば、約6割のケースでは、問題を作り込んだ開発者とは異なる別のメンバーが修正を行っていることになります。修正作業が一部のセキュリティ担当者やコアメンバーに偏ることで、コードを直接書いた開発者自身に学習の機会が十分に与えられず、結果として同様の記述ミスが繰り返されやすい環境が作られている可能性が指摘されています。
共通処理を集約した「util(ユーティリティ)」ファイルのリスク
もう一つの重要な知見として、プロジェクト内で「util」や「helper」といった名称が含まれるファイル(ユーティリティファイル)のセキュリティリスクが挙げられています。研究では、Linux、Django、Tomcatなど7つの著名なオープンソースプロジェクトの履歴データを抽出して比較を行いました。
ユーティリティファイルは、プロジェクト内の様々な場所から呼び出されるため再利用性が高い一方で、以下のような特徴を持つことがデータから示されました。
- 一般的なファイル(non-utilファイル)に比べて、コードの変更頻度(Churn)や編集に携わる開発者の数が多く、コードの複雑度も高くなりやすい傾向があります。
- 分析対象プロジェクト(Linux Kernelとsystemdを除く)において、ユーティリティファイルに含まれる脆弱性が「モジュール再発」する確率は50%を超えていました。これは、ユーティリティファイルが一度脆弱性修正の対象となっても、その後も高い確率で別の脆弱性を同じファイル内に抱え込みやすいことを意味します。
便利な共通モジュールとして利用されるユーティリティファイルですが、その特性上、一度問題が発生した際には周囲への影響が大きく、かつ再発の温床になりやすいため、コードレビューやテストにおいて一段と厳しい品質管理が求められます。
開発チームがセキュリティプロセスを向上させるためのポイント
本研究の分析結果から、開発チームが同じ脆弱性を繰り返さず、セキュリティプロセスを継続的に改善するための実践的なアプローチが考えられます。
- 脆弱性の「件数」評価からの脱却
脆弱性の報告件数のみでプロジェクトの安全性を評価するのを止め、過去の脆弱性タイプ(CWE)や、脆弱性が頻発しているモジュールを特定する「再発率」を指標として導入することが有効です。 - 知識の共有と当事者による修正の推奨
脆弱性が検出された際、単にセキュリティ担当者が修正をパッチとしてあてるだけでなく、そのコードを最初に記述した開発者にフィードバックを行い、可能な限り本人が修正に関わるように促します。これにより、個人の学習とチーム全体の知識共有が促進されます。 - ユーティリティファイルの厳格な監視
プロジェクト全体から頻繁に呼び出されるユーティリティやヘルパーファイルに対しては、コードの変更があった際に自動的に重点的なセキュリティスキャン(静的・動的解析)や、詳細なピアレビューを実施するプロセスを義務付けます。 - 開発プラクティスの段階的導入と追跡
CI/CDパイプラインへの静的検査(SAST)や自動ファズテストの組み込みは有効ですが、単にツールを入れるだけでなく、導入前後で同じ脆弱性タイプ(例:メモリバッファオーバーフロー、インプットバリデーション不備など)の再発率が実際に低下しているかを長期的にトラッキングすることが重要です。
まとめ
本研究が提示した「脆弱性再発(Vulnerability Recidivism)」の概念は、単に目の前の脆弱性を修正するだけでなく、開発プロセスそのものを健全化するための強力な視点を提供しています。1,213ものプロジェクトを対象とした大規模な分析データは、多くの開発現場において、過去の脆弱性の教訓が必ずしも次のコード混入防止に活かされていない現状を浮き彫りにしました。
コードの複雑さや脆弱性の深刻度とは独立して発生する「再発」だからこそ、その対策にはツールの導入だけでなく、開発者自身の学習機会の確保や知識共有プロセスの構築といった組織的なアプローチが求められます。自社で開発しているシステムや、利用しているオープンソースライブラリのセキュリティ評価を行う際には、ぜひ「再発率」という新たな視点を取り入れてみてはいかがでしょうか。
Webサービスや社内のセキュリティにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: