LLMを悪用した新たなサプライチェーン攻撃?「シェイプシフティング」によるコード隠蔽の脅威とは
公開日
セキュリティ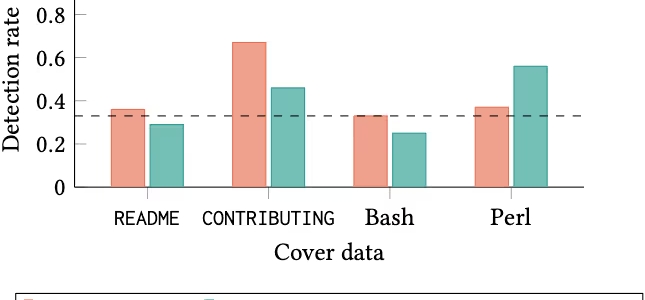
現代のソフトウェア開発において、外部のライブラリやオープンソースのコンポーネントを組み合わせてシステムを構築する手法は欠かせないものとなっています。しかし、こうした複雑なサプライチェーンは攻撃者にとっても格好の標的であり、一見無害に見えるデータの背後に悪意のある機能が巧妙に仕込まれる事件が相次いで発生しています。
本記事では、Mohammad Ebrahimi Fard氏らによる論文「Shape-Shifting Malicious Code in Software Backdoors via Language Models」に基づき、大規模言語モデル(LLM)を悪用して悪意のあるコードを自然なテキストに偽装する最新の攻撃手法と、その対策について解説します。
オープンソースを狙うサプライチェーン攻撃の死角
悪意のあるコードをプロジェクトに混入させるサプライチェーン攻撃を成功させるためには、周到な準備が必要です。特に透明性が高く、コミュニティによる相互レビューが盛んなオープンソースプロジェクトにおいては、組み込まれたコードがいかに自然に見えるかが攻撃の成否を分けます。
目につきにくい場所に潜むバックドア
従来のセキュリティ対策や研究は、ソフトウェアのソースコードそのものに潜むバックドアの特定に注力してきました。しかし、この視点だけでは不十分です。近年の著名な攻撃事例(XZ Utilsのバックドア事件など)では、攻撃者はソースコードではなく、普段は注意深くレビューされないバイナリのテストファイルなどに悪意のあるロジックを織り込んでいました。このように、ドキュメントやビルドスクリプトといった周辺ファイルが、攻撃の運び屋として機能してしまうリスクが高まっています。
LLMを悪用した「シェイプシフティング」の仕組み
Fard氏らが提案する新たな脅威モデルは、LLMの文章生成能力を活用し、悪意のあるペイロード(バックドアやシェルコードなど)を別の自然なデータ形式に変換する手法です。彼らはこれを「シェイプシフティング(姿を変える)コード」と呼んでいます。
攻撃と復元を分ける非対称な設計
この手法の最大の特徴は、コードを隠す「エンコード(符号化)」プロセスと、元のコードを復元する「デコード(復号)」プロセスが非対称に設計されている点です。攻撃者は自身の環境でLLMをフル活用して自然な偽装データを作成します。一方、被害者の環境で実行されるデコーダーにはLLMへのアクセス権限は必要なく、ごく僅かなコード量で処理を完了できるように作られています。
悪意あるコードを自然な文章に変換する技術
攻撃側のエンコーダーは、LLMの出力確率に基づく高度な検索アルゴリズムを用いてペイロードを隠蔽します。特定の文字(シグナル)や間隔(ブロックサイズ)を数学的な計算のトリガーとし、それらが組み合わさることで元の悪意あるバイト列が構成されるよう、文脈に合った自然なテキストを生成し続けます。
図表1:x86シェルコードを隠蔽した詩の例
上の図表は、実際に悪意のあるx86シェルコードが、英語の「詩」として出力された例です。一見すると開発者の苦労をユーモラスに綴った無害なテキストですが、所定の計算式を通すことで危険な実行コードへと変換されます。READMEファイルや貢献者向けガイド(CONTRIBUTING)など、プロジェクトに頻繁に含まれるドキュメントに紛れ込ませることが可能です。
警戒されにくい軽量なデコーダー
偽装されたデータから元のコードを取り出すデコーダーは、数行の短いスクリプトで記述できます。長大で複雑なコードは監査システムや人間の目に留まりやすいため、攻撃者はこれを極力小さく保ちます。
図表2:Perl、Python、Shellで記述されたデコーダーの例

図表2に示されるように、Perl、Python、Bashなど、様々な言語を用いて100バイトから120バイト程度のサイズでデコーダーを実装できます。既存のビルドスクリプトや設定ファイルの中にループ処理や文字列操作の一部として紛れ込ませることで、単なるデータ処理の記述にしか見えないよう偽装されます。
隠蔽されたコードは検知可能か?評価実験の結果
このような手法で隠蔽されたコードに対し、現在の私たちは適切に防御できるのでしょうか。Fard氏らの研究チームは、現実のバックドアコードを用いて複数の偽装ファイルを作成し、その検知難易度を測る実験を行いました。事前に28名の技術者を対象に、本物のファイル群の中に1つだけ生成された偽装ファイルを混ぜ、それを特定できるかを検証しています。
人間の目によるレビューの限界
実験に参加した対象者は、コードの隠蔽が行われていることは知らされず、不自然なファイルを見つけ出すよう指示を受けました。
図表3:ユーザー調査における参加者の偽装ファイル検出率
図表3のグラフが示す通り、大半のファイル形式において、参加者が偽装ファイルを正しく選び出した割合は偶然の確率(約33%)とほぼ同等でした。一部のファイル(CONTRIBUTINGファイルなど)では文章が不自然に長くなることで疑われやすくなる傾向があったものの、READMEファイルやShellスクリプトにおいては、人間の目で注意深くレビューしても不正なデータを見抜くことは極めて困難であることが証明されています。
AI生成テキスト検出ツールの実用性
人間の目が届かないのであれば、機械的な検出ツールに頼るアプローチが考えられます。研究では、AIが生成したテキストを見破るための最新の検出ツール(GPTZeroなど)を複数用いて、偽装データの検知を試みました。 しかし、結果としていずれのツールも実用的な防御手段にはなり得ませんでした。ソフトウェアプロジェクトにおける膨大なファイル群に対してこれらのツールを使用すると、無害なファイルまで「AI生成である」と誤検知する割合(偽陽性率)が高くなりすぎます。日々の活発な開発フローの中で頻発する警告に対処することは現実的ではありません。
プロジェクトを守るための推奨対策
コードの難読化や隠蔽技術が高度に発達し、LLMの自然言語生成能力と結びついた現在、提出された「データの内容そのもの」を解析して脅威を排除することは限界を迎えています。論文では、悪意のある変更が組み込まれる前のプロセスを強化するよう強く推奨しています。
貢献者の身元確認の徹底
ソフトウェアの重要なコンポーネントに対して変更を提案する貢献者(コントリビューター)については、より慎重な身元確認が必要です。誰がそのコードを記述したのかを検証し、怪しい貢献のパターンや不自然な活動履歴を持つアカウントからの申請には厳しい制限を設ける仕組みが求められます。
変更に対する説明責任と追跡可能性の確保
提出された変更に対しては、デジタル署名を用いたコミットの保証や、誰がどの部分の変更に責任を持つのかという出所情報(プロビナンス)を厳格に管理することが重要です。これにより、万が一プロジェクト内に不審な挙動や不可解なスクリプトが発見された際、原因箇所を即座に特定し、過去に遡って被害を抑え込むことが可能になります。
まとめ
LLMを活用した「シェイプシフティング・コード」は、従来のセキュリティ監査の目をすり抜け、ドキュメントやスクリプトを介してバックドアを侵入させる強力な手法です。人間によるレビューもAIによる検知も決定打に欠ける現状において、オープンソースプロジェクトを守るためには、開発に参加する人物の信頼性と変更プロセスの透明性を根本から見直す必要があります。ソフトウェアサプライチェーンの安全性を確保するためには、誰を受け入れ、どのように管理するのかというルール作りが、今後ますます重要になっていくでしょう。
Webサービスや社内のセキュリティにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: