AGENTS.mdは本当に役立つのか?AIコーディングエージェントにおけるコンテキストファイルの効果を検証
公開日
ソフトウェア開発の現場では、AIコーディングエージェントの導入が急速に進んでいます。その際、各リポジトリ固有のルールやツールの使い方をエージェントに正確に伝えるため、「AGENTS.md」や「CLAUDE.md」といったコンテキストファイルをプロジェクトのルートディレクトリに配置する手法が広く普及しています。
本記事では、チューリッヒ工科大学などの研究チームが発表した論文「Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?」に基づき、これらのコンテキストファイルが実際にエージェントのタスク完了能力を向上させているのかを検証した結果を解説します。
AIコーディングエージェントにおけるコンテキストファイルの役割と調査概要
新しいコードベースに参加する人間の開発者がドキュメントを読むように、AIコーディングエージェントにもプロジェクトの全体像や適切なコマンドを教える必要があります。AnthropicやOpenAIなどの主要なAIベンダーは、リポジトリ環境をエージェントに適応させるために、コンテキストファイルの作成を強く推奨しています。現在、GitHub上の6万以上の公開リポジトリにこのファイルが含まれていると報告されています。
本調査では、以下の4種類のコーディングエージェントと背後にあるLLMの組み合わせを対象に検証が行われました。
- Claude Code(Sonnet 4.5)
- Codex(GPT-5.2)
- Codex(GPT-5.1 mini)
- Qwen Code(Qwen3-30B-Coder)
検証は、既存の人気リポジトリを用いたデータセット(SWE-bench LITE)と、コンテキストファイルを導入しているニッチなリポジトリから新たに作成したデータセット(AgentBench)の両方を使用し、以下の3つの設定でタスクの成功率や推論コストの変化を比較しています。
- コンテキストファイルなし(None)
- LLMによる自動生成コンテキストファイルあり(LLM)
- 開発者が作成したコンテキストファイルあり(Human ※AgentBenchのみ)
検証結果:コンテキストファイルは成功率とコストにどう影響するのか
コンテキストファイルは、コーディングエージェントが正確かつ迅速にタスクを解決する助けになると期待されていました。しかし、実際の検証データは直感に反する結果を示しています。
図表1:モデル別のタスク成功率
 左が既存データセット(SWE-bench LITE)、右が新規データセット(AgentBench)。None(なし)、LLM(自動生成)、Human(開発者作成)を比較しています
左が既存データセット(SWE-bench LITE)、右が新規データセット(AgentBench)。None(なし)、LLM(自動生成)、Human(開発者作成)を比較しています
図表2:タスク完了までに要した平均ステップ数と推論コスト(USD)の比較(AgentBenchのみ抜粋)
| コンテキストファイル設定 | Sonnet 4.5 Steps(Cost) | GPT-5.2 Steps(Cost) | GPT-5.1 M. Steps(Cost) | Qwen3-30B Steps(Cost) |
|---|---|---|---|---|
| なし | 40.7(1.15) | 12.1(0.38) | 40.6(0.18) | 31.5(0.13) |
| 自動生成 | 46.5(1.33) | 13.1(0.57) | 46.9(0.20) | 34.2(0.15) |
| 開発者作成 | 45.3(1.30) | 13.6(0.54) | 46.6(0.19) | 32.8(0.15) |
LLM自動生成ファイルは成功率を下げ、コストを増大させる
現在、多くのAIツールが /init などのコマンドを使ってコンテキストファイルを自動生成する機能を提供しています。しかし調査の結果、LLMが生成したコンテキストファイルを与えられたエージェントは、ファイルがない状態(None)と比較して、全体的なタスクの成功率が平均して低下することが分かりました。
さらに、図表2が示す通り、タスク完了までに必要なステップ数がすべての環境で増加しています。その結果、LLMによる推論コストは平均して20%以上も跳ね上がる結果となりました。
開発者が作成したファイルは成功率をわずかに向上させる
一方で、人間(プロジェクトの開発者)が直接記述したコンテキストファイルを利用した場合、LLM生成ファイルよりも良好な結果が得られました。成功率はファイルなしの状態と比較して平均4%ほど向上しています。
研究チームの分析によると、LLMが自動生成したコンテキストファイルは、リポジトリ内の既存ドキュメントと内容が重複(冗長化)しがちです。それに対し、人間が作成したファイルには、リポジトリ内の他の場所には記述されていない独自の「追加情報」が含まれている傾向があり、これがタスク解決のヒントとなって精度の向上に寄与していると考察されています。
ただし、この場合でもエージェントのステップ数やコストは最大で19%増加しており、ファイルを読み込ませることによる計算リソースの負担は避けられないことが判明しました。
なぜコンテキストファイルは効果が薄いのか?行動ログの分析
コンテキストファイルがパフォーマンスを大きく引き上げない原因を探るため、研究チームはエージェントの行動ログ(ツール呼び出しの履歴)を詳細に分析しました。
指示には従うため、探索やテストの実行回数は増加する
コンテキストファイルが存在することで、エージェントはファイル内に記述されたツールやコマンドを律儀に使用しようとします。
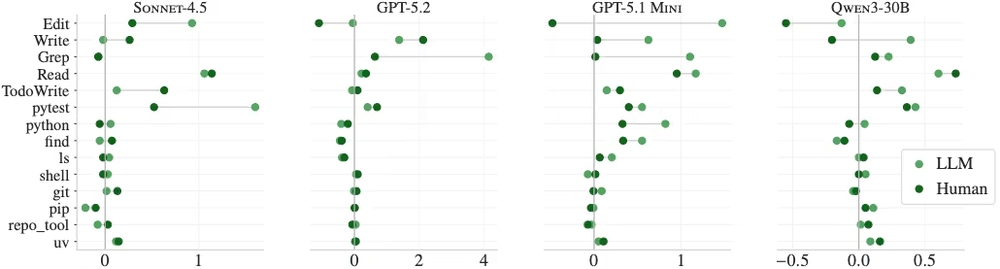
図表3:コンテキストファイルを追加した際のツール使用数の増減
 ゼロのラインより右側にある場合、該当ツールの使用回数が増加したことを意味します
ゼロのラインより右側にある場合、該当ツールの使用回数が増加したことを意味します
図表3を見ると分かるように、コンテキストファイルが追加されると、エージェントはコードの探索(grepやファイル読み込み)やテストコマンドの実行をより多く行うようになります。つまり、エージェントは指示を無視しているわけではなく、むしろ指示通りにリポジトリを広く探索し、丁寧にテストを実行しています。しかし、その手厚いプロセスがタスクの成功率に結びついていないのが実情です。
余分な指示がタスクを複雑にし、推論量を増加させている
行動が増えることは、エージェントにとってタスクの難易度が上がっていることを意味します。コンテキストファイルには、不要なリポジトリの全体像や、タスク解決に直接関係のないルールが含まれていることが多々あります。
図表4:タスク解決に使用された推論トークン数の比較
 コンテキストファイルを与えられると推論量が増加しています
コンテキストファイルを与えられると推論量が増加しています
最近のLLMは、複雑なタスクに対してより深く考える「適応的推論」の能力を備えています。図表4のデータから、コンテキストファイルを与えられたエージェントは、ファイルなしの状態と比較して最大22%も多く推論トークンを消費していることが確認されました。余分な指示がノイズとなり、エージェントを考え込ませ、結果としてコストを押し上げているのです。
結論:AGENTS.mdは必要最小限の記述にとどめる
本研究の結果から、リポジトリ全体を俯瞰するような巨大なコンテキストファイルは、コーディングエージェントの成功率を低下させ、コストを不必要に増加させることが分かりました。現時点のAIコーディングエージェントの能力を最大限に引き出すためには、以下の運用が推奨されます。
- LLMによる自動生成に頼らない: 自動生成された冗長なコンテキストファイルは、ノイズとなる可能性が高いため避けるべきです。
- 人間が必要最小限の要件だけを書く: 特定のフレームワーク固有のコマンドや、リポジトリで必須となる依存関係の解決手順など、ドキュメントに記載されておらずエージェントが自力で気づきにくい最小限の要件に絞って記述することが効果的です。
AIエージェントの技術は発展途上であり、ベンダーの推奨事項が必ずしも現場の最適解になるとは限りません。余計な情報を削ぎ落とし、シンプルにタスクへ集中させることが、現時点における最も賢いエージェントの活用方法と言えます。
生成AIの導入や活用にお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: