AIが意図通りに動かない?401事例から見えた「Cursor Rules」最適化のコツ
公開日
開発現場において、大規模言語モデル(LLM)を活用したAIコーディングアシスタントの導入が急速に進んでいます。しかし、AIにプロジェクトの意図に沿った的確なコードを生成させるためには、単発のプロンプトを工夫するだけでなく、既存のアーキテクチャやチームの規約といったシステム全体の背景情報(コンテキスト)を継続的に共有することが不可欠です。
本記事では、カリフォルニア大学アーバイン校の研究者らが発表した論文「Beyond the Prompt: An Empirical Study of Cursor Rules」(2026年)に基づき、オープンソースプロジェクトにおける「Cursor Rules」の実際の使われ方と、開発者がAIへ提供すべきコンテキストの分類について解説します。
開発者がAIに与えるべき5つのコンテキスト(分類体系)
本研究では、2025年にGitHub上から収集した401のオープンソースリポジトリを対象に、開発者がCursor Rules(.mdcファイル)を通じてAIにどのような指示を与えているか、定性的な分析を行いました。
分析の結果、提供されているコンテキストは大きく5つのカテゴリに分類できることがわかりました。
図表1:Cursor Rulesで提供されるコンテキストタイプの分類
| カテゴリ | 定義 | リポジトリの採用割合 |
|---|---|---|
| Project(プロジェクト) | ソフトウェアプロジェクトの環境や機能に関する説明 | 85% |
| Convention(規則) | プロジェクト内でコードを記述・整理するための基準 | 84% |
| Guideline(ガイドライン) | 特定の実践事項や避けるべき落とし穴への指示 | 89% |
| LLM Directive(LLMへの指示) | LLMがどのように応答を生成すべきかの直接的な指示 | 50% |
| Example(具体例) | 良い例・悪い例や基本テンプレートの提示 | 50% |
多くのリポジトリでは、「Project(プロジェクト情報)」「Convention(規約)」「Guideline(ガイドライン)」といった、従来のソフトウェア開発において人間向けに作成されてきたドキュメントと同様の情報をAIにも提供し、プロジェクトの一貫性を保とうとしていることが伺えます。
一方で注目すべきは、「LLM Directive(LLMへの指示)」の採用率が50%にとどまっている点です。これは人間向けのドキュメントには見られないAI特有の指示ですが、論文では採用率が低い理由として、開発者がまだLLM特有の指示の書き方に不慣れであるか、あるいは「そもそもこれらの指示が本当に必要なのか」確信を持てていない可能性を指摘しています。
プログラミング言語や開発領域によるルールの最適化
AIに与えるべき情報は、すべてのプロジェクトで一律ではありません。本研究では、使用する技術や領域によってルールの傾向が変わることも確認しています。
開発言語の特性(静的・動的)による情報量の調整
プログラミング言語の型システムの違いは、AIに提供すべきコンテキストの量と種類に直接的な影響を与えます。
図表2:プログラミング言語別の各コンテキストタイプの平均コード数
図表2が示す通り、Go、C#、Javaのような静的型付け言語を使用するプロジェクトでは、提供されるルールの総量が少ない傾向にあります。これは、コンパイル時に厳密な型チェックが行われるため、コード自体からAIが設計の意図を推論しやすく、追加のコンテキストをそれほど必要としないためと考えられます。
対照的に、JavaScriptやPHPなどの動的型付け言語では、より多くのコンテキストが記述されていました。特に、フロントエンド開発で多用されるJavaScriptやTypeScriptのプロジェクトでは、頻繁にアップデートされるフレームワークの独自ルールをAIに理解させるため、具体的なコード例(Example)が多く提示されています。
アプリケーションの複雑さに応じたコンテキストの変化
アプリケーションの開発領域(ドメイン)によっても、重視されるルールに違いが見られます。
図表3:アプリケーション領域別の各コンテキストタイプの平均コード数
図表3を見ると、プロジェクトの性質によって提供されるコンテキストに違いがあることがわかります。たとえば、データ分析(Data Analysis)やLLMエージェント開発のような、予測が難しく実行前に慎重な検討を要するプロジェクトでは、詳細なガイドライン(Guideline)が手厚く提供される傾向があります。
また、大規模なシステムインフラストラクチャ(System Infra.)やWeb開発など、多様なデータソースや既存ライブラリを組み合わせる複雑な環境では、LLMが自力で文脈を把握するのが困難なため、豊富な具体例(Example)による補完が多く見られます。
一方で、公式のオンラインリソースが豊富な一般的なWeb開発(Web Dev.)の領域では、AIが事前の学習データから一般的なベストプラクティスを十分に引き出せるためか、プロジェクト固有のルール(Project)の記述は比較的少なく抑えられていました。
Cursor Rules作成の実態と効率的な運用に向けて
開発者は、これらのルールをどのように作成し、運用しているのでしょうか。調査からは、効率化を求める実態と今後の課題が見えてきました。
既存ルールの流用(重複)の実態と注意点
調査対象となったCursor Rulesの全行のうち、約28.7%が他のリポジトリからの完全なコピー(重複)であることが判明しました。多くの開発者が、コミュニティで共有されているテンプレートを使用したり、似たようなプロジェクトからルールを流用したりしています。
図表4:コンテキストカテゴリ別のコード重複率
図表4はカテゴリ別の重複率を示しています。「LLM Directive(LLMへの指示)」の重複率は32%であり、プロジェクト情報やガイドラインといった他の主要カテゴリ(20%台)と比較して高い傾向にあります。このことから、プロンプトエンジニアリングに関連するAIの振る舞い指示は、プロジェクト間で使い回しやすい性質を持っていることが分かります。
しかし、プロジェクト固有の特性を考慮せずに汎用的なテンプレートに依存しすぎると、AIが一度に処理できる情報量(コンテキストウィンドウ)を無駄に圧迫し、本当に必要な独自の情報が埋もれてしまうリスクがあります。
プロジェクトの経過時間に伴うAIへの指示の変遷
リポジトリが作成されてからの期間によっても、ルールの内容に明確な変化が見られました。
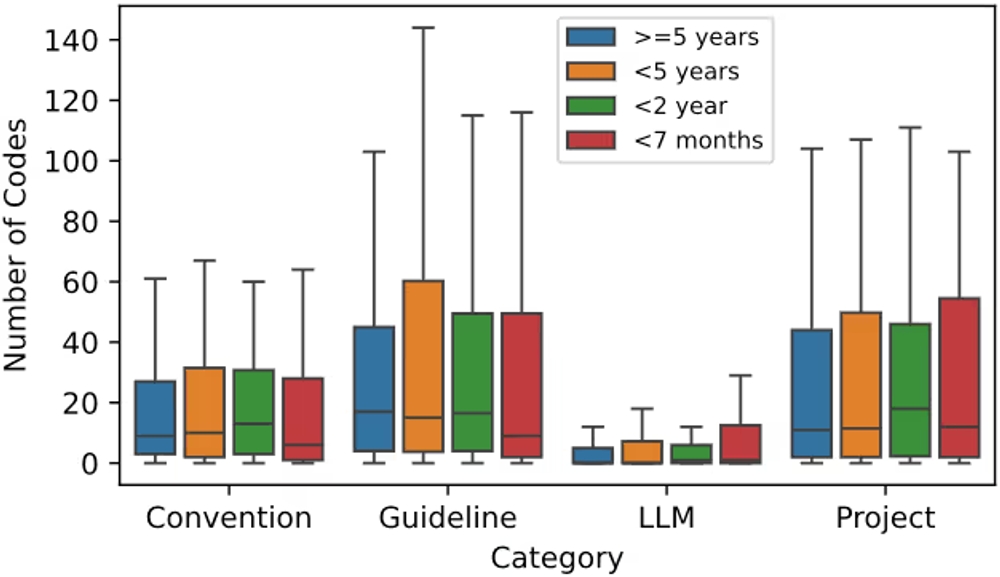
図表5:時間経過に伴う各カテゴリのコード数の推移
図表5は、リポジトリの作成からCursor Rulesが追加されるまでの経過期間別に、各カテゴリのコード数を示しています。全体として「LLM Directive(LLMへの指示)」の記述量自体は他のカテゴリに比べて少なめですが、リポジトリ作成からルール追加までの期間が短い(より新しい)プロジェクトほど、その記述量がわずかに多くなる傾向が見られます。
設立から間もない新しいプロジェクトほど、LLMの能力や限界を意識し、AIの振る舞いを制御するための具体的な指示を積極的に盛り込もうとする傾向が伺えます。
結論と今後の展望
AIコーディングアシスタントの性能を最大限に引き出すためには、汎用的なプロンプトのテクニックだけでなく、プロジェクト固有の環境、規約、そしてAIの振る舞いを制御する明確な指示を組み合わせた「コンテキストの設計」が不可欠です。
現在、多くの開発者が手探りでルールを作成したり、既存のテンプレートを流用したりしています。今後は、プロジェクトの言語やドメインに合わせて自動的に必要なコンテキストを抽出し、ルールを最適化してくれるようなツールの進化が期待されます。AIとの共同作業を円滑に進めるために、本研究で示された5つの分類や図表データを参考に、自身のプロジェクトのルールを見直してみてはいかがでしょうか。
生成AIの導入や活用にお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: